An Illustrated Guide to Elliptic Curve Cryptography Validation
Elliptic Curve Cryptography (ECC) has become the de facto standard for protecting modern communications. ECC is widely used to perform asymmetric cryptography operations, such as to establish shared secrets or for digital signatures. However, insufficient validation of public keys and parameters is still a frequent cause of confusion, leading to serious vulnerabilities, such as leakage of secret keys, signature malleability or interoperability issues.
The purpose of this blog post is to provide an illustrated description of the typical failures related to elliptic curve validation and how to avoid them in a clear and accessible way. Even though a number of standards1,2 mandate these checks, implementations frequently fail to perform them.
While this blog post describes some of the necessary concepts behind elliptic curve arithmetic and cryptographic protocols, it does not cover elliptic curve cryptography in detail, which has already been done extensively. The following blog posts are good resources on the topic: A (Relatively Easy To Understand) Primer on Elliptic Curve Cryptography by Nick Sullivan and Elliptic Curve Cryptography: a gentle introduction by Andrea Corbellini.
In elliptic curve cryptography, public keys are frequently sent between parties, for example to establish shared secrets using Elliptic curve Diffie–Hellman (ECDH). The goal of public key validation is to ensure that keys are legitimate (by providing assurance that there is an existing, associated private key) and to circumvent attacks leading to the leakage of some information about the private key of a legitimate user.
Issues related to public key validation seem to routinely occur in two general areas. First, transmitting public keys using digital communication requires to convert them to bytes. However, converting these bytes back to an elliptic curve point is a common source of issues, notably due to canonicalization. Second, once public keys have been decoded, some mathematical subtleties of the elliptic curve operations may also lead to different types of attacks. We will discuss these subtleties in the remainder of this blog post.
TL;DR
In general3, vulnerabilities may arise when applications fail to check that:
- The point coordinates are lower than the field modulus.
- The coordinates correspond to a valid curve point.
- The point is not the point at infinity.
- The point is in the correct subgroup.
An Illustrated Guide to Validating ECC Curve Points
Elliptic curves are curves given by an equation of the form 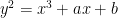
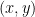
These values, called coordinates (more specifically, affine coordinates), are defined over a field. For use in Cryptography, we work with coordinates defined over a finite field. For the purpose of this blog post, we will concentrate our efforts on the field of integers modulo 




Mathematically, a value larger than the field modulus is equivalent to its reduced form (that is, in the 
In ECC, a public key is simply a point on the curve. Since curve points are generally first encoded to byte arrays before being transmitted, the first step when receiving an encoded curve point is to decode it. This is what we identified earlier as the first area of confusion and potential source of vulnerabilities. Specifically, what happens when the integer representation of the coordinates we decoded are larger than the field modulus?
This is the first common source of issues and the reason for our first validation rules:
Check that the point coordinates are lower than the field modulus.
What can go wrong? If the recipient does not enforce that coordinates are lower than the field modulus, some elliptic curve point operations may be incorrectly computed. Additionally, different implementations may have diverging interpretations of the validity of a point, possibly leading to interoperability issues, which can be a critical issue in consensus-driven deployments.
In the figure below, this means that the point coordinates should be rejected if they are not in the white area in the bi-dimensional plane.

Since both coordinates are elements of this finite field, it might seem that an elliptic curve point could theoretically take any value in the white area above. However, not all pairs of

This is another common source of issues and where our second validation rule arises:
Check that the point coordinates correspond to a valid curve point (i.e. that the coordinates satisfy the curve equation).
What can go wrong? If the recipient of a public key fails to verify that the point is on the curve, an attacker may be able to perform a so-called invalid curve attack6. Some point operations being independent of the value of 
In practice, curve points are rarely sent as pairs of coordinates, which we call uncompressed. Indeed, the 

- no solutions (in case
does not have a square root in the field, i.e. is not a quadratic residue), in which case the point should be rejected; or
- two solutions,
, due to the fact that
. However, all coordinates must lie in the
range, which are all positive numbers. Since we’re working in the field of integers modulo
, which lies in the correct range.
Hence, when compressing a point, an additional byte of data is used to distinguish the correct
- Compressed point:
0x02 || xif y is even and0x03 || xif y is odd; - Uncompressed point:
0x04 || x || y.7
Any other value for the first byte should result in the curve point being ignored. Point compression has a significant benefit in that it ensures that the point is on the curve, since in case there is no solution, implementation should reject the point.
Now, the careful reader may have realized that the set of points in the figure above is incomplete. In order for this set to form a group (in the mathematical sense), and be useful in cryptography, it needs to be supplemented with an additional element, the point at infinity. This point, also called neutral element or additive identity, is the element 



Since the point at infinity is not on the curve, it does not have well-defined
Implementations sometimes fail to properly distinguish the point at infinity, and this is where our third validation rule comes from:
Check that the point is not the point at infinity.
What can go wrong? Since multiplying the point at infinity by any scalar results in the point at infinity, an adversary may force the result of a key agreement to be zero if the legitimate recipient fails to check that the point received is not the point at infinity. This goes against the principle of contributory behavior, where some protocols require that both parties contribute to the outcome of an operation such as a key exchange. Failure to enforce this check may have additional negative consequences in other protocols.
Recall that the curve order, say 
In cryptography, to ensure that the discrete logarithm problem is hard, curves are selected in such a way that they consist of one subgroup with large, prime order, say 



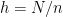
To illustrate this notion, consider the figure below in which we have further subdivided our fictitious set of elliptic curve points into two groups. When performing operations on elliptic curve points, we want to stick with operations on points in the larger, prime-order subgroup, identified by the blue points below.

And this is where our last validation rule comes from:
Check that the point is in the correct subgroup.
This can be achieved by checking that 

What can go wrong? A malicious party sending a point in the orange subgroup, for example as part of an ECDH key agreement protocol, would result in the honest party performing operations limited to that small subgroup. Thus, if the recipient of a public key failed to check that the point was in the correct subgroup, the attacker could perform a so-called small subgroup attack (also known as subgroup confinement attacks) and learn information about the legitimate party’s private key12.
Does that apply to all curves?
While the presentation above is fairly generic and applies in a general sense to all curves, some curves and associated constructions were created to prevent some of these issues by design.
NIST curves (e.g. P-256) and the Bitcoin curve (secp256k1)
These curves have a cofactor value of 1 (namely, 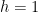
Curve25519
Curve25519, proposed by Daniel J. Bernstein and specified in RFC 7748, is a popular curve which is notably used in TLS 1.3 for key agreement.
Although Curve25519 has a cofactor of 8, some functions using this curve were designed to prevent cofactor-related issues. For example, the X25519 function used to perform key agreement using Curve25519 mandates specific checks and performs key agreement using only
Implementations MUST accept non-canonical values and process them as if they had been reduced modulo the field prime. The non-canonical values are 2^255 – 19 through 2^255 – 1 for X25519.
This seems to address most issues discussed in this post. However, there has been some debate13 over the claimed optional nature of these checks.
With the popularity of Curve25519 and the desire for cryptographers to design more exotic protocols with it, the cofactor value of 8 resurfaced as a potential source of problems. Ristretto was designed as a solution to the cofactor pitfalls. Ristretto is an abstraction layer, on top of Curve25519, which essentially restricts curve points to a prime-order subgroup.
Double-Odd Elliptic Curves
Finally, a strong contender in the secure-by-design curve category is the Double-Odd family of elliptic curves, recently proposed by Thomas Pornin. These curves specify a strict and economical encoding, preventing issues with canonicalization and, even though their cofactor is not trivial, a prime order group is defined on them, similar in spirit to Ristretto’s approach, preventing subgroup confinement attacks.
Conclusion
With the ubiquitous use of elliptic curve cryptography, failure to validate elliptic curve points can be a critical issue which is sadly still commonly uncovered during cryptography reviews. While standards and academic publications provide ample directions to correctly validate curve points, implementations still frequently fail to follow these steps. For example, a vulnerability nicknamed Curveball was reported in January 2020, which allowed attacker to perform spoofing attacks in Microsoft Windows by crafting public points. Recently, we also uncovered a critical vulnerability in a number of open-source ECDSA libraries, in which the verification function failed to check that the signature was non-zero, allowing attackers to forge signatures on arbitrary messages, see the technical advisory Arbitrary Signature Forgery in Stark Bank ECDSA Libraries.
This illustrated guide will hopefully serve as an accessible reference on why and how point validation should be performed.
Thank you
The author would like to thank Eric Schorn and Giacomo Pope for their detailed review and helpful feedback.
References
- Standards for efficient cryptography, SEC 1: Elliptic Curve Cryptography, Section 3.2.2.1 Elliptic Curve Public Key Validation Primitive.
- NIST Special Publication 800-56A, Section 5.6.2.3.2 FFC Partial Public-Key Validation Routine and 5.6.2.3.3 ECC Full Public-Key Validation Routine.
- That is, unless using an elliptic curve that was designed specifically to address these potential issues, we will come back to that at the end of this blog post.
- Specifically, implementations may handle values that are larger than the field modulus in different ways. They may reject non-reduced values (i.e., non-canonical encodings), accept non-reduced values and reduce them modulo the prime order, or accept non-reduced values and discard the most significant bit(s). An interesting example happened with the cryptocurrency Zcash, where different implementations had distinct interpretations regarding the validity of curve points. Some details can be found in a blog post by Henry de Valence, as well as in a public report following a cryptography review performed by NCC Group.
- Note that this figure does not represent an actual elliptic curve; it is just an arbitrary diagram designed for illustrative purposes.
- Ingrid Biehl, Bernd Meyer and Volker Müller. “Differential Fault Attacks on Elliptic Curve Cryptosystems”. In: Advances in Cryptology – CRYPTO 2000, 20th Annual International Cryptology Conference, Santa Barbara, California, USA, August 20-24, 2000, Proceedings. 2000, pp. 131–146.
- Note that there is a hybrid form starting in
0x06defined in ANSI X9.62, but this format is very rarely used in practice. - Note that some curves and alternate point representations (for instance, when working in projective coordinates) may allow the point at infinity to have a well-defined representation.
- Standardized in FIPS PUB 186-4: Digital Signature Standard (DSS).
- Standardized in SEC 2: Recommended Elliptic Curve Domain Parameters.
- The paper Taming the many EdDSAs provides some very interesting discussions around ambiguities in the Ed25519 signature verification equations (which is based on Curve25519). These ambiguities led to different interpretations of the validity of signatures, which resulted in implementations returning different validity results for some signatures, which could be critical in consensus-driven applications.
- Chae Hoon Lim and Pil Joong Lee. “A Key Recovery Attack on Discrete Log-based Schemes Using a Prime Order Subgroup”. In: Advances in Cryptology – CRYPTO ’97, 17th Annual International Cryptology Conference, Santa Barbara, California, USA, August 17-21, 1997, Proceedings. 1997, pp. 249–263.
- See https://moderncrypto.org/mail-archive/curves/2017/000896.html.