Real World Cryptography Conference 2022
The IACR’s annual Real World Cryptography (RWC) conference took place in Amsterdam a few weeks ago. It remains the best venue for highlights of cryptographic constructions and attacks for the real world. While the conference was fully remote last year, this year it was a 3-day hybrid event, live-streamed from a conference center in charming central Amsterdam with an audience of about 500 cryptographers.
Some members of our Cryptography Services team attended in person, while others shifted their schedules by six hours to watch the talks live online. In this post, we share summaries of some of our favorite talks. Have a stroopwafel and enjoy!
- An Evaluation of the Risks of Client-Side Scanning
- On the (in)security of ElGamal in OpenPGP
- “They’re not that hard to mitigate”: What Cryptographic Library Developers Think About Timing Attacks
- Zero-Knowledge Middleboxes
- Drive (Quantum) Safe! — Towards Post-Quantum Security for Vehicle-to-Vehicle Communications
- ALPACA: Application Layer Protocol Confusion – Analyzing and Mitigating Cracks in TLS Authentication
- Lend Me Your Ear: Passive Remote Physical Side Channels on PCs
- CHIP and CRISP — Password-based Key Exchange: Storage Hardening Beyond the Client-Server Setting
- Trust Dies in Darkness: Shedding Light on Samsung’s TrustZone Cryptographic Design
An Evaluation of the Risks of Client-Side Scanning
On the second day of the conference, Matthew Green presented an extremely interesting talk based on a paper that was co-authored with Vanessa Teague, Bruce Schneier, Alex Stamos and Carmela Troncoso. He began by noting that the continued deployment of end-to-end encryption (and backup) over the past few years has only increased the concerns of the law enforcement community regarding content access. At the same time, technical opinions seem to be converging on the unsuitability of key escrow solutions for these purposes. Thus, as content transport becomes encrypted and goes dark, this naturally motivates an interest in client-side scanning technologies.
Until recently, law enforcement access requests primarily involved singular and exceptional circumstances, perhaps requiring subpoenas or other safeguards. Some may recall the FBI demanding access to domestic terrorism suspect’s phones.
However, law enforcement’s access request underwent a significant expansion in October 2019, as can be seen in US Attorney General William Barr’s (and others) open letter to Mark Zuckerberg of Facebook. The letter noted the benefits of current safety systems operating on ALL (not singular) content and how end-to-end encryption will effectively shut them down, while requesting Facebook not proceed with its plans to deploy encrypted messaging until solutions can be developed to provide lawful access. The supporting narrative has also expanded from domestic terrorism, as the letter now highlights “…illegal content and activity, such as child sexual exploitation and abuse, terrorism, and foreign adversaries‚ attempts to undermine democratic values and institutions…”. Given the benefit of perfect hindsight, the word “foreign” may have been unnecessary!
As it stands today, sent messages are generally scanned on a central server to detect suspect content by either A) a media hashing algorithm, or B) a neural network. While each approach has a variety of strengths and weaknesses, both involve proprietary and sensitive internal mechanisms that operate on unencrypted source material. The migration of this technology onto client devices is not straightforward.
One cryptographic innovation is to use two-party computation (2PC) where the client has the content, the server provides the scanning algorithm, and neither learns anything about the other unless there is a match. An example of this was published in August 2021 as the Apple PSI System. Nonetheless, Matthew Green highlighted a number of remaining risks.
Risk 1 is from mission creep. While current proposals center around child sexual abuse material (CSAM), the Barr memo clearly hints at the slippery slope leading to other content areas. In fact, the BBC reported on a similar scenario involving shifting commitments in “Singapore reveals Covid privacy data available to police“.
Risk 2 is from unauthorized surveillance. In this scenario, systems may be unable to detect if/when malicious actors inject unauthorized content into the scanning database or algorithm. There is disagreement on whether this can be reliably audited to prevent misuse or abuse.
Risk 3 is from malicious false positives. All systems produce false positives where a harmless image may trigger a detection (e.g., hash collision) event. Attempts to limit this by keeping algorithm/models/data secret are unrealistic as demonstrated by the rapid reverse engineering of Apple’s NeuralHash function as noted by Bruce Schneier.
In any event, Apple announced an indefinite delay to its deployment plans in August 2021. However, as enormous pressure remains on providing content access to law enforcement, the idea will not simply go away. As these client-side scanning technologies may represent the most powerful surveillance system ever imagined, it is imperative that we find a way to make them auditable and abuse-resistant prior to deployment.
If you are interested in finding out more, see the paper “Bugs in our Pockets: The Risks of Client-Side Scanning” at https://arxiv.org/abs/2110.07450.
— Eric Schorn
On the (in)security of ElGamal in OpenPGP
☠️ Ahoy, everyone! ☠️
Cryptography’s most notorious pirate , Luca De Feo, returns to Real World Crypto to discuss the dangers of ambiguity in cryptographic standards, based on his work with Bertram Poettering and Alessandro Sorniotti. In particular, the focus of the presentation (YouTube, slides) is on how flexibility in a key generation standard can result in practical plaintext recovery.
The story begins with the OpenPGP Message Format RFC 4880, which states
Implementations MUST implement DSA for signatures, and ElGamal for encryption. Implementations SHOULD implement RSA […]
Although RSA is usually the standard choice, any implementation that follows the RFC comes packaged with the option to instead use ElGamal (over a finite field, not an elliptic curve) and it’s here that lies the problem.
Unlike RSA, ECDH, or (EC)DSA, ElGamal doesn’t have a fixed standard. Instead, the protocol is usually implemented from either the original paper, or The Handbook of Applied Cryptography (Chapter 8).
ElGamal Encryption
ElGamal encryption is simple enough that we can describe it here. A public key contains a prime modulus 
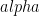
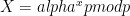



To decrypt a message, usually one computes 
However, if an attacker can compute 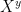
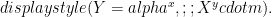

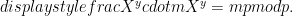
Parameter generation
The attack described below comes from interoperability of differing implementations that disagree on the assumptions made on the parameters of ElGamal encryption.
Let’s first look at how the primes can be chosen. We write our primes in the form 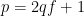

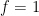
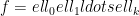

Next up is how the generators 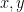

![x,y in [1,p-1]](https://s0.wp.com/latex.php?latex=x%2Cy+in+%5B1%2Cp-1%5D&bg=ffffff&fg=000&s=0&c=20201002)
However, certain specifications assume that the prime
Cross Configuration Attacks
In isolation, either of the above set-ups can be used safely. However, a vulnerability can occur when two distinct implementations interoperate running under different assumptions. The attack described is exposed when a public key that uses a Schnorr prime with a primitive generator is sent to an implementation that produces short ephemeral keys.
Precisely, if an attacker can find the factors of 
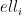
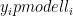


Of the 800,000 ElGamal PGP public keys surveyed, 2,000 keys were exposed to practical plaintext recovery via computing the ephemeral keys when messages were encrypted using GnuPGG, Botan, Libcrypto++ or any other library implementing the short key optimization.
Side-Channels
Additionally, some ephemeral keys were leaked by side channel attacks. Generally, FLUSH+RELOAD (instruction cache) or PRIME+PROBE (data cache) were used to leak data, but additional discrete logarithms must be computed to fully recover the ephemeral keys.
In the Libcrypto++ and Go implementations, the side-channel attacks are said to be straightforward, but for GnuPG, the attacks are much harder. If the short keys are generated by GnuPG, key recovery is estimated to be within reach for nation state attackers, but for Libcrypto++, as the keys are even shorter, a lucky attacker may be able to recover the key on commodity resources.
A summary of the work, including a live demo, is available on IBM’s site, and the paper itself is available on eprint.
— Giacomo Pope
“They’re not that hard to mitigate”: What Cryptographic Library Developers Think About Timing Attacks
Ján Jančár presented a joint work with Marcel Fourné, Daniel De Almeida Braga, Mohamed Sabt, Peter Schwabe, Gilles Barthe, Pierre-Alain Fouque and Yasemin Acar. The corresponding paper has been made available on eprint. It is a survey paper that tries to investigate why timing attacks are still found in cryptographic libraries: are cryptographic library developers aware that they exist, do they try to mitigate them, do they know about existing tools and frameworks for detection and prevention of timing issues?
To answer such questions, the authors contacted 201 developers of 36 “prominent” cryptographic libraries, to fill a survey with questions about the subject, with free-text answers. Unconstrained answers were chosen because the cryptographic libraries cover a very large spectrum of target systems, usage contexts, and optimization goals (performance, portability,…) that could not be properly captured with a multiple-choice questionnaire. The paper details the methodology used for interpretation of the results. The authors draw several conclusions from the analysis of the survey results, the main one being nicely summarized by the quote in the title of the talk: developers know and care about such timing issues, but think that they are not that hard to avoid, and thus do not prioritize investigating and using tools that could help in that area.
Of course, while side-channel leaks are an objective fact that can be measured with great precision, the choice of the “right” method to avoid them during development is a lot more subjective and developers have opinions. Having been myself a participant to that survey (as the developer of BearSSL), my own opinions put me slightly at odds with their conclusion, because I don’t use tools to tell me whether I wrote constant-time code, though it is not because I would consider that problem to be “not too hard”. It is more that I took from day 1 the extreme (extremist?) stance of always knowing how my code is translated to machine instructions, and how these get executed in the silicon. This is certainly not easy to do, and it takes time to write decent code under these conditions! But it is a necessary condition in order to achieve the size optimizations (in RAM and ROM) that BearSSL aims for, as well as ensuring correctness and decent enough performance. Constant-time behavior is a natural side-effect of developing that way. In other words, I don’t need a tool to tell me whether my code is constant-time or not, because if I cannot answer that right away then I have already failed to achieve my goals (even if the executable turns out to be, indeed, constant-time). What would be most useful to me would be a way to instruct the compiler about which data elements are secret and must not be handled in a non-constant-time way, but while some toolchains begin to include such extensions, I cannot use them without compromising portability, which is another paramount goal of BearSSL.
Notwithstanding, I support all the recommendations of the authors, in particular the following:
- Cryptographic libraries should eliminate all timing leaks, not just those that are felt to be potentially exploitable in practice (it may be noted that “security enclaves” such as Intel’s SGX or Samsung’s TrustZone are the perfect situation for a side-channel attacker, allowing exploitation of the tiniest leaks).
- Compilers should offer ways for developers to tag secret values for which compilers should produce only constant-time code, or at least warn upon use in a non-constant-time construction. Such tagging should furthermore be standardized as much as possible, de facto if not de jure, so that portability issues don’t prevent its use.
- Standardization bodies should mandate use of constant-time code, at least for cryptographic operations. Ideally, other standardization bodies should also require adequate support, in the programming languages, and instruction set architectures.
An unfortunate reality is that even getting the compiler to issue an instruction sequence that seems constant-time is only a part of the question. The underlying hardware will often execute operations in a way that adheres to the abstract model of the advertised architecture, but may introduce timing-based side channels; this is an increasing cause of concern, as hardware platforms become larger and more complicated, and may now include themselves arbitrary translation layers, including JIT compilers, undocumented and hidden from the application developers. In the long-term, only a fully vertical approach, with guarantees at all layers from the programming language to the transistor, may provide a strong solution to timing-based side channels.
— Thomas Pornin
Zero-Knowledge Middleboxes
Paul Grubbs presented his and co-workers’ work on Zero-Knowledge Middleboxes, enabling privacy-preserving enforcement of network policies using zero-knowledge protocols. Middleboxes are systems that mediate communications between other systems, to perform a number of services, including inspection, transformation and filtering of network traffic. They are commonly found in corporate environments, universities, ISPs, etc. and in any environments that typically require enforcement of certain policies, mostly for compliance, security and performance purposes, or to share network resources amongst several devices. When middleboxes are employed for compliance and security in a given environment, their services conflict with users’ privacy (and potentially — and counter-intuitively — with the security of information exchanged between mediated systems, because of the reliance on vendors’ middleboxes and meddler-in-the-middle infrastructure’s secure implementation, for instance).
Paul Grubbs et al. propose to address this seemingly irreconcilable difference with zero-knowledge proof (ZKP) methods, so middlebox users can have both privacy and policy enforcement. They set out the following objectives for their research:
- Don’t weaken encryption.
- Network environment/Middleboxes can enforce policies as they did before.
- No server changes should be required.
Furthermore, circumvention should be still possible via “inner” encryption (VPN/Tor/etc.).
In a zero-knowledge proof protocol, one party, the prover, proves to another party, the verifier, that a statement is true, while preserving confidentiality of information. Zero-knowledge proofs satisfy several properties:
- Completeness: if both proof and verification are correct, and if the statement is true, then the prover is convinced of the fact provided in the statement.
- Soundness: a malicious prover cannot convince the verifier of a false statement.
- Zero-knowledge: a malicious verifier cannot access confidential information.
Paul described a solution architecture centered around a zero-knowledge middlebox, in which:
- A client joins the managed network, and gets the policy that is to be enforced.
- The client and server establish key material, and encrypt traffic as usual, e.g. using TLS 1.3.
- The client sends the encrypted traffic and a statement that the ciphertext contains compliant traffic.
- The managed network middlebox verifies the proof, and blocks traffic on failure, otherwise it passes the encrypted traffic to the server and back.
It was not clear whether the solution would work or not for Paul and his team, when it was initially fleshed out. It relied on adapting the zero-knowledge “machinery” with complex protocols such as TLS 1.3, and its key schedule. However, they found that ZKPs applied to TLS 1.3 are close to practical, an exciting outcome of their research.
Paul then proceeded with describing the solution in more detail, specifically circuit models for zero-knowledge middleboxes (ZKMB). He explained that building a ZKMB is to construct a circuit, with a three-step pipeline:
- Channel opening: decrypt ciphertext, and output message.
- Parse + extract: find and output relevant data from message.
- Policy check: verify data is compliant.
Paul described how they applied these steps to TLS 1.3, to determine if the decrypted plaintext is compliant with a given policy, and to DNS-over-HTTPS and DNS-over-TLS (respectively DoH and DoT), to filter out unauthorized encrypted DNS queries.
One of the sample challenges that Paul and his team had to address, was how to provide a key consistency proof, because TLS record decryption is not bound to a given key. (Paul worked on similar challenges before.) This was achieved at a high level, with judicious use of the TLS 1.3 message and handshake transcript, as components of the ZK proof.
The team managed to fulfill the objectives they set out at the beginning of their research:
- Don’t weaken encryption: use standard encryption, and the zero-knowledge property of ZKPs to conceal private information.
- Network environments/Middleboxes can enforce policies as they did before, using ZKPs’ soundness property. Clients cannot bypass middleboxes, and the soundness property prevents clients from lying.
- No server changes, facilitating easier deployment of the solution. Middleboxes don’t need to forward proofs to servers.
And (internet censorship) circumvention is still possible.
They achieved these goals with close to practical performance. For instance, in their encrypted DNS case study, they managed to generate a proof of policy compliance in 3 seconds. Further work on improving performance is already showing great promises.
This is great research work, with an obvious positive impact on privacy, and possibly an improvement on the security and reliability of access to resources gated by middleboxes, in which they do not have to interfere with encrypted traffic, with inline decryption, parsing and re-encryption of traffic.
— Gérald Doussot
Drive (Quantum) Safe! — Towards Post-Quantum Security for Vehicle-to-Vehicle Communications
Nina Bindel presented joint work with Sarah McCarthy, Hanif Rahbari, and Geoff Twardokus that outlines practical steps that can be taken to bring post-quantum (PQ) security to connected vehicle messaging. Vehicle-to-vehicle (V2V) communication encompasses applications where vehicles exchange situational awareness information in the form of Basic Safety Messages (BSMs) containing data such as location, heading, velocity, acceleration, and braking status over a wireless channel. Widespread adoption of V2V could prevent or decrease the severity of accidents, reduce congestion, and improve driving efficiency leading to less pollution. Clearly, these benefits can only be realized if V2V messages are authentic and trustworthy.
In brief:
- Communication is broadcast-based wireless (variant of WiFi or cellular);
- BSMs are broadcast at a rate of 10 per second;
- BSMs are authenticated using IEEE 1609.2 certificates with ECDSA signatures;
- Signed BSMs must be small (< 2304 bytes) and fast (~1ms generation/verification);
- Vehicles rotate their certificate every few minutes for privacy reasons;
- Certificates are only valid for 1 week, then discarded;
- Certificates are only included with a signed BSM every 5 messages;
- Vehicles currently have an average lifespan of 15+ years;
- ECDSA is vulnerable to quantum attacks.
In light of the above, the authors consider the challenge of providing post-quantum protection without compromising on the existing application requirements. The size constraint of 2304 bytes includes the BSM data, the signature/metadata, and the certificate/public key when necessary. Therefore, the authors conclude that a naive replacement of ECDSA with any existing PQ scheme is simply not possible.
As a first step, a hybrid approach is proposed. Each classical ECDSA-based certificate is paired with a PQ certificate using Falcon. During BSM transmission that includes a certificate, both the ECDSA and Falcon certificates are included, along with only an ECDSA signature. This allows both certificates to be communicated without violating the size constraints, but without providing PQ security on this particular message. In all other messages, a hybrid signature is included, such that the resulting signature is valid if either at least one of the classical or PQ signatures are secure. Therefore, once certificates are communicated, the remaining messages achieve PQ security. This comes at the cost of increasing the resulting message size by a factor of 5-6, with signed BSMs increasing from ~144 bytes to ~834 bytes.
To improve on the hybrid proposal, the authors propose a partially-PQ hybrid. Under the observation that CA keys are somewhat long-lived, but the keys used to sign BSMs are only used for short durations during a 1-week period, the authors propose continuing to sign BSMs with a classical ECDSA key, but to certify these ECDSA keys using a PQ scheme. In order to launch a successful attack, a quantum adversary would need to compromise the ECDSA private key during this short usage window, and would not gain the ability to certify adversarially-controlled keys. To maintain flexibility and the ability to use a PQ algorithm where the PQ certificate size may exceed the maximum BSM size, the PQ certificate may be fragmented and sent in pieces alongside with consecutive BSMs. Under this approach, all BSMs are signed with the ECDSA key to provide classical security, and after sufficiently many BSMs are received, a PQ signature certifying the ECDSA key is established.
The proposed solutions are interesting because they remain within the constraints established by existing standards. The overhead required to accommodate the partially-PQ approach does substantially impact the theoretical performance of V2V messaging, but an optimized partially-PQ approach can still achieve ~60% of the throughput of the classical system, despite the much greater key sizes required by PQ approaches. While there may be several more challenges in bringing PQ security to connected vehicle communications, this presentation provides solid first steps in realizing this outcome.
— Kevin Henry
ALPACA: Application Layer Protocol Confusion – Analyzing and Mitigating Cracks in TLS Authentication
In this talk, Marcus Brinkmann presented the ALPACA attack, which exploits misconfigurations of TLS servers to negate web security by reflecting TLS requests to servers running non-intended applications. For example, they show that in some realistic scenarios, such as when a wildcard certificate is used by both an HTTP and an FTP server for TLS server authentication, an attacker can redirect an HTTP request to an FTP server instead and use this to steal cookies or to allow the execution of arbitrary code on the client device (who believes it came from the HTTP server). Their team focused on the case of redirecting HTTP requests to SMTP, IMAP, POP3, or FTP servers, but note that redirection attacks are possible between other pairs of applications as well.
The idea behind the ALPACA attack is not new — according to their website, this attack vector was known since 2001 and was exploited in an attack against a specific implementation in 2015. However, this talk generalized this idea, by formalizing it as a class of cross-protocol attacks, and did an internet-wide scan of servers running these TLS applications that show that there is still a large number (>100,000) of vulnerable servers.
As mitigations, the authors suggest using cryptographic mitigations instead of addressing this attack at the application layer: they show that it is possible to use the strict Application Layer Protocol Negotiation (ALPN) and Server Name Indication (SNI) extensions in TLS to prevent this attack, despite the fact that neither of these extensions was originally intended as a security measure for TLS.
This talk demonstrates how protocols that have been proven secure can still be targeted by attacks, by considering scenarios outside of the scope of the proof. Additionally, it highlights how difficult it is to mitigate attacks on the internet at large, even if they’ve been known for a long time. On the flip side, it also provides a silver lining — by showing how our existing tools sometimes already do (or can easily be modified to do) more than we originally designed them for.
— Elena Bakos Lang
Lend Me Your Ear: Passive Remote Physical Side Channels on PCs
In the last, and arguably most glamorous, talk of the conference’s first session, Daniel Genkin and Roei Schuster presented a very real-world demonstration of a physical side-channel attack. Their talk was based on research to be presented at the upcoming Usenix Security ’22 conference, and showed how built-in microphones in commodity PCs capture electromagnetic leakage that can be used to perform impressive side-channel attacks.
Side-channel attacks can broadly be placed in two categories: attacks exploiting software-based side-channels (such as microarchitectural attacks, including Spectre and Meltdown, or timing attacks exploiting timing differences in the processing of sensitive data), and physical side-channel attacks where the leakage emitted by a processing component can be used to extract sensitive information (examples of leakages include the power consumption of a device, or electromagnetic emanations).
While physical side-channel attacks can be extremely powerful — they are essentially passive attacks that require only measuring the target’s emissions — they are sometimes swept under the rug since they require physical proximity to the victim’s computer. In this talk, the speakers presented a remote physical side-channel attack which can be carried out without running any code on the victim’s machine.
This research sprouted from an interesting observation: modern-day laptops have an internal microphone which is physically wired to the motherboard of the computer. That motherboard also hosts the processor, which emits electromagnetic radiations. The wiring of that microphone essentially acts as an electromagnetic probe, which then picks up small emanations produced by the processor. Since microphone input is nowadays frequently transmitted over the internet (think, for example, audio being transmitted by VoIP or conferencing software), that side-channel leakage may be observed remotely.
As a demonstration, Daniel proceeded to display the spectrogram (i.e. the graph of frequencies over time) of the signal captured in real-time by a laptop’s microphone. In addition to picking up the voice of the speaker on the lower end of the frequency spectrum, some patterns in the high-frequency spectrum could be observed, stemming from the electromagnetic emissions of the processor. By running a demo program performing some heavy processor operations, the speaker highlighted how the shape of these high-frequency patterns changed, clearly indicating that the processor’s emissions was dependent on the computation being performed. The second speaker, Roei, then proceeded to showcase three remote attacks leveraging this novel side-channel leakage.
In a first example, Roei demonstrated an attack in which an adversary could remotely identify the website that a victim visited. To do so, a neural network was trained to classify the different leakage patterns produced when accessing different websites by the victim’s device remotely, only based on the processor’s electromagnetic emissions.
In a second example, the speaker presented a cryptographic key extraction attack on ECDSA. This scenario was a little more complex in that it leveraged an implementation with a known timing side-channel leakage in the ECDSA nonce scalar multiplication operation, and also required the usage of deterministic ECDSA RFC 6979 in order to obtain enough information to correctly implement the attack. However, the researchers were able to successfully mount an attack extracting the secret key from leakage traces of around 20k signed messages.
The third example showcased how this side-channel leakage could also be used to gain a competitive advantage when playing video games. In a recorded demonstration, the speaker showed an instance of the video game Counter-Strike, where an attacker and a victim were competing against each other while also being connected via VoIP (a seemingly likely scenario in the competitive video game community). The attack essentially exploits the fact that a player’s machine renders the opponent’s avatar even if that opponent is not in the visual field of that player. Since rendering is a processor-heavy operation, the attacker is able to gain an advantage in the game by determining the player’s proximity only by observing the electromagnetic emissions from the victim’s processor!
This talk presented some impressive new results on remote side-channel leakage and demonstrated three real-world attacks that are worth watching, paving the way for exciting future work.
— Paul Bottinelli
CHIP and CRISP — Password-based Key Exchange: Storage Hardening Beyond the Client-Server Setting
Eyal Ronen spoke about his work (with Cas Cremers, Moni Naor, and Shahar Paz) on password-authenticated key exchange (PAKE) protocols in the symmetric setting. We’ve been told many times over the years that passwords are “dead” — and yet, as Eyal pointed out, they are still the most ubiquitous form of authentication.
CHIP and CRISP are protocols that allow two parties to use a (possibly low-entropy) password to derive a shared secret key without needing to re-enter the plaintext password as input every time. They are designed for a symmetric, many-to-many setting: each entity (device) knows the password, and any device can initiate the protocol with any other device. (Compare this with the asymmetric, client-server setting where only the client knows the password.)
CHIP (Compromise Hindering Identity-based PAKE) and CRISP (Compromise Resilient Identity-based Symmetric PAKE) are “identity-based” PAKEs designed to be resistant to key compromise impersonation attacks: compromising one device does not allow impersonating other parties to that device.
CRISP, which the rest of this section will focus on, is a strong PAKE: whatever derivative of the password is stored on the devices resists pre-computation attacks. Resistance to such attacks is particularly important when passwords are involved, since password distributions mean these attacks would scale well.
Each device generates a password file in a one-time process after which the password can be deleted (and does not need to be re-input). This process uses a device’s identity, which is a (not necessarily unique) tag. Specifically, in CRISP, the device with identity id and password pwd stores 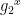
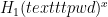
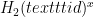
When two devices want to establish an authenticated channel, they first perform a kind of identity-based key agreement using the salted values in their password file blinded by a session-specific random value. This is a Diffie-Hellman style exchange, plus some pairings, to establish a shared secret and verify each other’s identity. The shared secret is then fed into any symmetric PAKE protocol (such as CPace) to get the final shared key.
This structure makes it clear why CRISP is called a compiler that transforms a symmetric PAKE into one that’s identity-based and resilient to compromise. But why is the PAKE necessary to obtain the shared key when the step before allows the two parties to compute a shared secret? The paper describes (in section 6.3) how replacing the PAKE with a KDF would not be secure, as it would allow an adversary to make multiple offline passwords guesses based on just one key agreement step with another party. Whether the full strength of a symmetric PAKE is needed is unclear (and possibly future work!).
Perhaps one of the trickiest practical aspects of identity-based PAKEs is handling identities: since there is no (central) key distribution center, any party that knows the password can claim to have any identity. This would make it difficult to provide effective revocation.
For the details of CHIP and CRISP, see the paper on eprint. You can also check out the authors’ implementations of CHIP and CRISP on GitHub.
— Marie-Sarah Lacharité
Trust Dies in Darkness: Shedding Light on Samsung’s TrustZone Cryptographic Design
Alon Shakevsky demonstrated ways in which a closed-source TrustZone that is deployed at Android’s massive scale (approximately 100 million Samsung devices) can have well-known vulnerabilities that go unnoticed for many years. This talk presented the research that Alon published along with Eyal Ronen and Avishai Wool. To carry out this research, they first reverse-engineered Android’s hardware-backed keystore and demonstrated that an IV reuse attack was possible, then they examined the impact of this finding in higher level protocols. They also demonstrated that the version that used proper randomness was still susceptible to a downgrade attack that made it just as vulnerable.
As is common with Trusted Execution Environment (TEE) designs, all cryptographic key materials (mostly used for signing or encryption) must reside inside the TrustZone. However, according to this research, in some Samsung Galaxy devices, there was support for exporting the encrypted key blobs. The question now became, how’s this key encryption key (referred to as a Hardware Derived Key or HDK in the slides) generated? It turns out that a permanent device-unique 256-bit AES key called the Root Encryption Key (REK) along with a salt and IV were used to derive this key: encrypted_blob = AES-GCM(HDK = KDF(REK, salt), IV, key_material). As Alon pointed out, this is a fragile construction since if the HDK is static in an application, then it becomes highly vulnerable to an IV reuse attack. Then the next question is, how are the salt and IV chosen? In 2 out of 3 versions that were examined, the salt was derived from application-provided ID and data, and the IV was also provided by the application. Given this construction, a privileged attacker who observes the encrypted_blob for key A can extract its IV and salt and use them to fabricate the encrypted_blob for a known key B. The final step is to XOR the two encrypted_blobs (i.e. the ciphertexts of keys A and B) with key B (in plaintext) to recover key A.
Once details of the IV reuse attack were worked out, Alon proceeded to describe the extent of the exploits that are possible without a user’s involvement. The story gets more painful when you learn that, in an attempt to provide backwards compatibility, the version that used randomized salts (V20-s10) was in fact susceptible to a downgrade attack.
The key takeaway messages are:
- If AES in GCM mode must be used in an application, use a nonce misuse resistant variant such as AES-GCM-SIV to prevent IV reuse. Or, always generate a random IV without exposing it in the API.
- Never allow clients to choose the encryption version and downgrade to a latent code path. This is especially important if backwards compatibility is a requirement.
As Alon pointed out towards the end of his talk, this research demonstrated the downside of composable protocols, such as WebAuth, which allow key attestation via a hardware keystore that could be compromised: once the vulnerability is disclosed, servers have no way of verifying whether a given certificate was generated on a vulnerable device or not. In addition, the closed source and vendor-specific TEE implementations enable these types of issues to go unnoticed for an extended time period. Alon indicated that he advocates for a uniform open standard by Google for the Keymaster Hardware Abstraction Layer and Trusted Applications to close this gap.
Finally, their paper “Trust Dies in Darkness: Shedding Light on Samsung’s TrustZone Keymaster Design” on eprint demonstrates a working FIDO2 WebAuth login bypass and a compromise of Google’s Secure Key Import. The appendix section provides some insights and code snippets that could be helpful for future research in this area. It is worth mentioning that Samsung has already patched their devices and issued 2 CVEs that are relevant to this work: CVE-2021-25444 for the IV reuse vulnerability and CVE-2021-25490 for the downgrade attack.
— Parnian Alimi